本系列文章分两部分,是对离线 Web 开发的简要、高级介绍。在第一部分中,我们运行了一个基本的 Service Worker,它缓存了我们的应用程序资源。现在让我们将其扩展为支持离线。
文章系列
- 设置
- 实施(您现在就在这里!)
制作一个 `offline.htm` 文件
接下来,让我们添加一些代码来检测应用程序何时处于离线状态,如果处于离线状态,则将用户重定向到(缓存的)`offline.htm`。
但是等等,如果 Service Worker 文件是自动生成的,我们如何手动添加自己的代码呢?好吧,我们可以为 importScripts 添加一个条目,它会告诉我们的 Service Worker 导入我们指定的脚本。它通过 Service Worker 的原生 importScripts 函数执行此操作,该函数命名很贴切。我们还将 `offline.htm` 文件添加到我们静态缓存的文件列表中。以下突出显示了新文件
new SWPrecacheWebpackPlugin({
mergeStaticsConfig: true,
filename: "service-worker.js",
importScripts: ["../sw-manual.js"],
staticFileGlobs: [
//...
"offline.htm"
],
// the rest of the config is unchanged
})现在,让我们进入我们的 `sw-manual.js` 文件,并添加代码以在用户处于离线状态时加载缓存的 `offline.htm` 文件。
toolbox.router.get(/books$/, handleMain);
toolbox.router.get(/subjects$/, handleMain);
toolbox.router.get(/localhost:3000\/$/, handleMain);
toolbox.router.get(/mylibrary.io$/, handleMain);
function handleMain(request) {
return fetch(request).catch(() => {
return caches.match("react-redux/offline.htm", { ignoreSearch: true });
});
}我们将使用之前看到的 toolbox.router 对象来捕获我们所有顶级路由,如果主页面无法从网络加载,则返回(希望是缓存的)`offline.htm` 文件。
这是本文中为数不多的几次,您将直接看到承诺的使用,而不是使用异步语法,主要是因为在这种情况下,仅仅添加一个 .catch() 实际上比设置一个 try{} catch{} 块更容易。
`offline.htm` 文件将非常基础,只是一些从 IndexedDB 读取缓存的书籍并将其以基本表格形式显示的 HTML。但在展示之前,让我们先了解如何实际使用 IndexedDB(如果您只想现在查看,它在这里)
你好世界,IndexedDB
IndexedDB 是一个浏览器内数据库。它非常适合启用离线功能,因为它可以在没有网络连接的情况下访问,但它绝不仅限于此。
该 API 早于 Promise,因此它是基于回调的。我们将使用原生 API 逐步介绍所有内容,但在实践中,您可能希望使用自己的辅助方法(用 Promise 包装功能)或第三方实用程序来包装和简化它。
让我再说一遍:IndexedDB 的 API 很糟糕。以下是 Jake Archibald 说他甚至不会直接教它
我总是教授底层 API 而不是抽象,但我对 IDB 会例外。
— Jake Archibald (@jaffathecake) 2017 年 12 月 2 日
我们仍然会介绍它,因为我真的很想让您看到它的真实面目,但请不要让它吓跑你。有很多简化的抽象,例如 dexie 和 idb.
设置我们的数据库
让我们在 sw-manual 中添加代码,该代码订阅 Service Worker 的激活事件,并检查我们是否已经设置了 IndexedDB;如果没有,我们将创建它,然后用数据填充它。
首先,是创建部分。
self.addEventListener("activate", () => {
//1 is the version of IDB we're opening
let open = indexedDB.open("books", 1);
//should only be called the first time, when version 1 does not exist
open.onupgradeneeded = evt => {
let db = open.result;
//this callback should only ever be called upon creation of our IDB, when an upgrade is needed
//for version 1, but to be doubly safe, and also to demonstrade this, we'll check to see
//if the stores exist
if (!db.objectStoreNames.contains("books") || !db.objectStoreNames.contains("syncInfo")) {
if (!db.objectStoreNames.contains("books")) {
let bookStore = db.createObjectStore("books", { keyPath: "_id" });
bookStore.createIndex("imgSync", "imgSync", { unique: false });
}
if (!db.objectStoreNames.contains("syncInfo")) {
db.createObjectStore("syncInfo", { keyPath: "id" });
evt.target.transaction
.objectStore("syncInfo")
.add({ id: 1, lastImgSync: null, lastImgSyncStarted: null, lastLoadStarted: +new Date(), lastLoad: null });
}
evt.target.transaction.oncomplete = fullSync;
}
};
});代码很凌乱且手动;正如我所说,您可能希望在实践中添加一些抽象。一些关键点:我们检查将要使用的对象存储(表),并在需要时创建它们。请注意,我们甚至可以创建索引,我们可以在书籍存储上看到,使用 imgSync 索引。我们还创建了一个 syncInfo 存储(表),我们将使用它来存储上次同步数据的时间信息,因此我们不会过分频繁地向服务器发出请求,询问更新。
事务完成后,在最底部,我们调用 fullSync 方法,该方法会加载我们所有的数据。让我们看看它是什么样子。
执行初始同步
以下是同步代码的相关部分,该代码会重复调用我们的端点以加载我们的书籍,逐页加载,并将每个结果添加到 IDB 中。同样,这使用了零抽象,因此预计会有很多膨胀。
请参阅 此 GitHub gist 以获取完整的代码,其中包括一些额外的错误处理和在完成最后一页时运行的代码。
function fullSyncPage(db, page) {
let pageSize = 50;
doFetch("/book/offlineSync", { page, pageSize })
.then(resp => resp.json())
.then(resp => {
if (!resp.books) return;
let books = resp.books;
let i = 0;
putNext();
function putNext() { //callback for an insertion, with indicators it hasn't had images cached yet
if (i < pageSize) {
let book = books[i++];
let transaction = db.transaction("books", "readwrite");
let booksStore = transaction.objectStore("books");
//extend the book with the imgSync indicated, add it, and on success, do this for the next book
booksStore.add(Object.assign(book, { imgSync: 0 })).onsuccess = putNext;
} else {
//either load the next page, or call loadDone()
}
}
});
}putNext() 函数是真正完成工作的函数。这充当每次成功插入成功的回调。在实际生活中,我们希望有一个不错的添加每本书的方法,将其包装在 promise 中,以便我们可以执行简单的 for of 循环,并 await 每次插入。但这是“普通”解决方案,至少是其中之一。
我们在插入每本书之前对其进行修改,将 imgSync 属性设置为 0,以指示此书尚未缓存其图像。
并且在我们用尽最后一页并且没有更多结果后,我们调用 loadDone(),以设置一些元数据,指示我们上次执行完整数据同步的时间。
在实际生活中,这是同步所有这些图像的最佳时机,但让我们改为按需由 Web 应用本身执行,以演示 Service Worker 的另一项功能。
在 Web 应用和 Service Worker 之间通信
让我们假设让书籍封面在 Service Worker 运行时用户下次访问我们的页面时加载是一个好主意。让我们让我们的 Web 应用向 Service Worker 发送一条消息,然后 Service Worker 会接收它,然后同步书籍封面。
从我们的应用程序代码中,我们尝试向正在运行的 Service Worker 发送一条消息,指示它同步图像。
在 Web 应用中
if ("serviceWorker" in navigator) {
try {
navigator.serviceWorker.controller.postMessage({ command: "sync-images" });
} catch (er) {}
}在 `sw-manual.js` 中
self.addEventListener("message", evt => {
if (evt.data && evt.data.command == "sync-images") {
let open = indexedDB.open("books", 1);
open.onsuccess = evt => {
let db = open.result;
if (db.objectStoreNames.contains("books")) {
syncImages(db);
}
};
}
});在 sw-manual 中,我们有代码来捕获该消息,并调用 syncImages() 方法。接下来让我们看看它。
function syncImages(db) {
let tran = db.transaction("books");
let booksStore = tran.objectStore("books");
let idx = booksStore.index("imgSync");
let booksCursor = idx.openCursor(0);
let booksToUpdate = [];
//a cursor's onsuccess callback will fire for EACH item that's read from it
booksCursor.onsuccess = evt => {
let cursor = evt.target.result;
//if (!cursor) means the cursor has been exhausted; there are no more results
if (!cursor) return runIt();
let book = cursor.value;
booksToUpdate.push({ _id: book._id, smallImage: book.smallImage });
//read the next item from the cursor
cursor.continue();
};
async function runIt() {
if (!booksToUpdate.length) return;
for (let book of booksToUpdate) {
try {
//fetch, and cache the book's image
await preCacheBookImage(book);
let tran = db.transaction("books", "readwrite");
let booksStore = tran.objectStore("books");
//now save the updated book - we'll wrap the IDB callback-based opertion in
//a manual promise, so we can await it
await new Promise(res => {
let req = booksStore.get(book._id);
req.onsuccess = ({ target: { result: bookToUpdate } }) => {
bookToUpdate.imgSync = 1;
booksStore.put(bookToUpdate);
res();
};
req.onerror = () => res();
});
} catch (er) {
console.log("ERROR", er);
}
}
}
}我们正在打开之前创建的 imageSync 索引,并读取所有值为零的书籍,这意味着它们尚未同步其图像。booksCursor.onsuccess 将会反复调用,直到没有剩余书籍;我使用它将所有书籍放入一个数组中,此时我会调用 runIt() 方法,该方法会遍历所有书籍,为每个书籍调用 preCacheBookImage()。此方法将缓存图像,并且如果没有不可预见错误,则会在 IDB 中更新书籍以指示 imgSync 现在为 1。
如果您想知道为什么我要费尽心机地将所有书籍从游标保存到一个数组中,然后再调用 runIt(),而不是仅仅遍历游标的结果,并边走边缓存和更新,那么——事实证明,IndexedDB 中的事务有点奇怪。它们在您让事件循环让出控制权时完成,除非您在事务提供的某个方法中让事件循环让出控制权。因此,如果我们离开事件循环去执行其他操作,例如发出网络请求以拉取图像,那么游标的事务将完成,并且如果我们稍后尝试继续从中读取,我们将收到错误。
手动更新缓存。
让我们总结一下,看看 preCacheBookImage 方法,该方法实际上会拉取封面图像并将其添加到相关的缓存中(但前提是它还没有在那里)。
async function preCacheBookImage(book) {
let smallImage = book.smallImage;
if (!smallImage) return;
let cachedImage = await caches.match(smallImage);
if (cachedImage) return;
if (/https:\/\/s3.amazonaws.com\/my-library-cover-uploads/.test(smallImage)) {
let cache = await caches.open("local-images1");
let img = await fetch(smallImage, { mode: "no-cors" });
await cache.put(smallImage, img);
}
}如果书籍没有图像,我们就完成了。接下来,我们检查它是否已经被缓存——如果是,我们就完成了。最后,我们检查 URL,并找出它属于哪个缓存。
local-images1 缓存名称与之前相同,我们在动态缓存中设置了它。如果相关图像还没有在那里,我们就会获取它并将其添加到缓存中。每个缓存操作都会返回一个 promise,因此异步/等待语法可以很好地简化操作。
测试一下
按照目前的设置,如果我们清除服务工作者(在开发工具、下面或通过打开一个新的隐身窗口),

…那么我们第一次查看应用程序时,所有书籍都会被保存到 IndexedDB。

当我们刷新时,图像同步将会发生。所以,如果我们从一个已经下载这些图像的页面开始,我们会看到我们的普通服务工作者将它们保存到缓存(假设我们延迟了 ajax 调用,以便我们的服务工作者有机会安装),这些就是我们在网络选项卡中看到的事件。

然后,如果我们导航到其他地方并刷新,我们将不会看到任何对这些图像的网络请求,因为我们的同步方法已经在缓存中找到了所有内容。
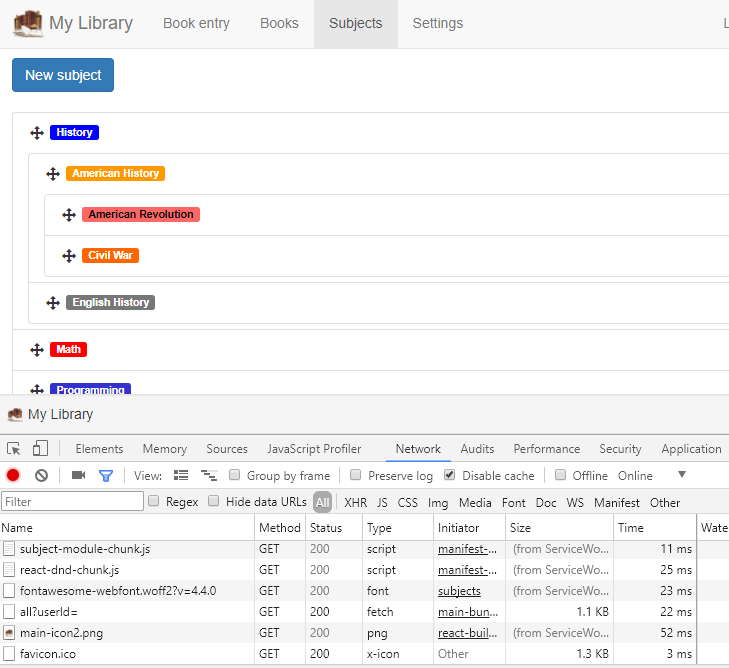
如果我们再次清除服务工作者,并从同一个页面开始(该页面**没有**从其他地方下载这些图像),然后刷新,我们会看到下载这些图像的网络请求,并将这些图像同步到缓存。

然后,如果我们导航回使用这些图像的页面,我们将不会看到缓存这些图像的调用,因为它们已经缓存了;此外,我们将看到这些图像被服务工作者从缓存中检索出来。

我们由 `sw-toolbox` 提供的 `runtimeCaching` 和我们自己的手动代码都协同工作,使用同一个缓存。
它起作用了!
如承诺,以下是 `offline.htm` 页面
<div style="padding: 15px">
<h1>Offline</h1>
<table class="table table-condescend table-striped">
<thead>
<tr>
<th></th>
<th>Title</th>
<th>Author</th>
</tr>
</thead>
<tbody id="booksTarget">
<!--insertion will happen here-->
</tbody>
</table>
</div>let open = indexedDB.open("books");
open.onsuccess = evt => {
let db = open.result;
let transaction = db.transaction("books", "readonly");
let booksStore = transaction.objectStore("books");
var request = booksStore.openCursor();
let rows = ``;
request.onsuccess = function(event) {
var cursor = event.target.result;
if(cursor) {
let book = cursor.value;
rows += `
<tr>
<td><img src="${book.smallImage}" /></td>
<td>${book.title}</td>
<td>${Array.isArray(book.authors) ? book.authors.join("<br/>") : book.authors}</td>
</tr>`;
cursor.continue();
} else {
document.getElementById("booksTarget").innerHTML = rows;
}
};
}现在让我们告诉 Chrome 假装离线,然后测试一下

酷!
从这里去哪里?
我们仅仅触及了皮毛。你的用户可以从多个设备更新这些数据,并且每个设备都需要以某种方式保持同步。你可以定期擦除你的 IDB 表格并重新同步;让用户在需要时手动触发重新同步;或者你可以雄心勃勃地尝试在你的服务器上记录所有你的变动,让每个设备上的服务工作者请求自上次运行以来发生的所有变化,以便同步。
这里最有趣的解决方案是 PouchDB,它可以为你完成这个同步工作;缺点是它被设计用来与 CouchDB 一起工作,你可能正在使用也可能没有使用它。
同步本地更改
最后一段代码,让我们考虑一个更容易解决的问题:将你的 IndexedDB 与你的用户正在使用你的 Web 应用程序的此刻所做的更改同步。我们已经在服务工作者中拦截了 fetch 请求,因此监听正确的变动端点、运行它,然后查看结果并相应地更新 IndexedDB 应该很容易。让我们看一看。
toolbox.router.post(/graphql/, request => {
//just run the request as is
return fetch(request).then(response => {
//clone it by necessity
let respClone = response.clone();
//do this later - get the response back to our user NOW
setTimeout(() => {
respClone.json().then(resp => {
//this graphQL endpoint is for lots of things - inspect the data response to see
//which operation we just ran
if (resp && resp.data && resp.data.updateBook && resp.data.updateBook.Book) {
syncBook(resp.data.updateBook.Book);
}
}, 5);
});
//return the response to our user NOW, before the IDB syncing
return response;
});
});
function syncBook(book) {
let open = indexedDB.open("books", 1);
open.onsuccess = evt => {
let db = open.result;
if (db.objectStoreNames.contains("books")) {
let tran = db.transaction("books", "readwrite");
let booksStore = tran.objectStore("books");
booksStore.get(book._id).onsuccess = ({ target: { result: bookToUpdate } }) => {
//update the book with the new values
["title", "authors", "isbn"].forEach(prop => (bookToUpdate[prop] = book[prop]));
//and save it
booksStore.put(bookToUpdate);
};
}
};
}这可能看起来比你希望的复杂一点。我们只能读取一次 fetch 响应,并且我们的应用程序线程也需要读取它,因此我们首先会克隆响应。然后,我们将运行一个 `setTimeout()`,以便我们可以尽快将原始响应返回到 Web 应用程序/用户,并在之后做我们需要的操作。不要仅仅依靠 `respClone.json()` 中的 promise 来做到这一点,因为 promise 使用微任务。我会让 Jake Archibald 解释这到底意味着什么,但简而言之,它们可能会使主事件循环饥饿。我不够聪明,无法确定这是否适用于这里,所以我只是使用了 `setTimeout` 的安全方法。
由于我使用的是 GraphQL,响应格式是可预测的,并且很容易看到我是否只执行了感兴趣的操作,如果是这样,我可以重新同步受影响的数据。
进一步阅读
这里的一切都由 这本由 Tal Ater 撰写的书 深入浅出地解释。如果你有兴趣了解更多,你无法找到比这更好的学习资源。
对于一些更直接、更快捷的资源,这里有一篇来自 MDN 关于 IndexedDB 的文章,以及来自 Google 的服务工作者简介和离线食谱。
临别寄语
让你的用户即使在没有网络连接的情况下也能用你的 Web 应用程序做一些有用的事情,这是 Web 开发人员获得的一种了不起的新能力。但正如你所见,这不是一件容易的事。希望这篇文章让你对需要期待什么有了一个现实的认识,并对完成此任务所需做的事情有一个不错的介绍。
文章系列
- 设置
- 实施(您现在就在这里!)
你能分享最终结果作为 github 仓库吗?
它在我的书单项目中,链接在第 1 部分。大多数相关的服务工作者代码可以在这里找到,尽管
https://github.com/arackaf/booklist/blob/master/react-redux/sw-manual.js
虽然其中很多还没有使用,因为我需要对我的项目进行一些更新才能真正做到这一点——但当然,在编写这篇文章时,它都经过了测试和运行。