GraphQL 越来越受欢迎,开发人员一直在寻找能轻松设置快速、安全且可扩展的 GraphQL API 的框架。在本文中,我们将学习如何使用身份验证和细粒度数据访问控制(授权)创建可扩展且快速的 GraphQL API。例如,我们将构建一个具有注册和登录功能的 API。该 API 将与用户和机密文件有关,因此我们将定义高级授权规则,以指定登录用户是否可以访问某些文件。
通过使用 FaunaDB 的原生 GraphQL 和安全层,我们获得了在几分钟内设置此类 API 所需的所有工具。 FaunaDB 有一个免费层,因此您可以通过在 https://dashboard.fauna.com/ 创建帐户轻松地进行操作。由于 FaunaDB 自动提供必要的索引并将每个 GraphQL 查询转换为一个 FaunaDB 查询,因此您的 API 也是尽可能快的(没有 n+1 问题!)。
设置 API 很简单:插入一个架构,我们就可以开始操作了。让我们开始吧!
用例:用户和机密文件
我们需要一个示例用例来演示安全性和 GraphQL API 功能如何协同工作。在这个示例中,有 **用户** 和 **文件**。一些文件可以被所有用户访问,而另一些文件仅供经理访问。以下 GraphQL 架构将定义我们的模型
type User {
username: String! @unique
role: UserRole!
}
enum UserRole {
MANAGER
EMPLOYEE
}
type File {
content: String!
confidential: Boolean!
}
input CreateUserInput {
username: String!
password: String!
role: UserRole!
}
input LoginUserInput {
username: String!
password: String!
}
type Query {
allFiles: [File!]!
}
type Mutation {
createUser(input: CreateUserInput): User! @resolver(name: "create_user")
loginUser(input: LoginUserInput): String! @resolver(name: "login_user")
}查看架构时,您可能会注意到 createUser 和 loginUser 突变字段已使用名为 @resolver 的特殊指令进行注释。这是 FaunaDB GraphQL API 提供的指令,它允许我们为给定的查询或突变字段定义自定义行为。由于我们将使用 FaunaDB 的内置身份验证机制,因此我们需要在导入架构后在 FaunaDB 中定义此逻辑。
导入架构
首先,让我们将示例架构导入到一个新数据库中。使用您的凭据登录到 FaunaDB 云控制台。如果您还没有帐户,可以在几秒钟内免费注册。
登录后,从主页点击“新建数据库”按钮

选择新数据库的名称,然后点击“保存”按钮:

接下来,我们将把上面列出的 GraphQL 架构导入到我们刚刚创建的数据库中。为此,创建一个名为 schema.gql 的文件,其中包含架构定义。然后,从左侧边栏中选择 GRAPHQL 选项卡,点击“导入架构”按钮,然后选择新创建的文件:

导入过程将创建所有必要的数据库元素,包括集合和索引,以备份架构中定义的所有类型。它会自动创建您的 GraphQL API 正常运行所需的一切。
您现在拥有一个功能齐全的 GraphQL API,您可以在 GraphQL playground 中开始测试。但是我们还没有数据。更具体地说,我们想创建一些用户来开始测试我们的 GraphQL API。但是,由于用户将是我们身份验证的一部分,因此它们是特殊的:它们具有凭据,可以被模拟。让我们看看如何创建一些具有安全凭据的用户!
用于身份验证的自定义解析器
请记住,createUser 和 loginUser 突变字段已使用名为 @resolver 的特殊指令进行注释。createUser 正是我们需要开始创建用户的工具,但是架构并没有真正定义如何创建用户;而是用 @resolver 标记。
通过用自定义解析器(例如 @resolver(name: "create_user"))标记特定的突变,我们通知 FaunaDB 此突变尚未实现,但将由一个 用户定义函数 (UDF) 实现。由于我们的 GraphQL 架构不知道如何表达这一点,因此导入过程只会创建一个函数模板,我们仍然需要填充它。
UDF 是一个自定义 FaunaDB 函数,类似于存储过程,它允许用户在 Fauna 的查询语言 (FQL) 中定义量身定制的操作。然后,该函数用作注释字段的解析器。
我们需要一个自定义解析器,因为我们将利用内置的身份验证功能,而这些功能无法在标准 GraphQL 中表达。FaunaDB 允许您为任何数据库实体设置密码。然后,可以使用 Login 函数模拟此数据库实体,该函数返回具有某些权限的令牌。此令牌持有的权限取决于我们将编写的访问规则。
让我们继续实现 createUser 字段解析器的 UDF,以便我们可以创建一些测试用户。首先,从左侧边栏中选择 Shell 选项卡

如前所述,导入过程中已创建了一个模板 UDF。调用时,此模板 UDF 会打印一条错误消息,指出它需要使用正确的实现进行更新。为了用预期行为更新它,我们将使用 FQL 的 Update 函数。
因此,让我们将以下 FQL 查询复制到基于 Web 的 shell 中,然后点击“运行查询”按钮
Update(Function("create_user"), {
"body": Query(
Lambda(["input"],
Create(Collection("User"), {
data: {
username: Select("username", Var("input")),
role: Select("role", Var("input")),
},
credentials: {
password: Select("password", Var("input"))
}
})
)
)
});您的屏幕应该类似于

create_user UDF 将负责正确创建用户文档以及密码值。密码存储在名为 credentials 的特殊对象内的文档中,该对象是加密的,无法通过任何 FQL 函数检索。因此,密码安全地保存在数据库中,使其无法从 FQL 或 GraphQL API 中读取。密码稍后将用于通过名为 Login 的专用 FQL 函数对用户进行身份验证,如下所述。
现在,让我们通过以下 FQL 查询添加支持 loginUser 字段解析器的 UDF 的正确实现
Update(Function("login_user"), {
"body": Query(
Lambda(["input"],
Select(
"secret",
Login(
Match(Index("unique_User_username"), Select("username", Var("input"))),
{ password: Select("password", Var("input")) }
)
)
)
)
});复制上面列出的查询并将其粘贴到 shell 的命令面板中,然后点击“运行查询”按钮

login_user UDF 将尝试使用给定的用户名和密码凭据对用户进行身份验证。如前所述,它通过 Login 函数执行此操作。Login 函数验证给定的密码是否与与要进行身份验证的用户文档一起存储的密码匹配。请注意,数据库中存储的密码在登录过程中不会输出。最后,如果凭据有效,则 login_user UDF 会返回一个名为秘密的授权令牌,该令牌可以在后续请求中用于验证用户的身份。
解析器到位后,我们将继续创建一些示例数据。这将让我们尝试我们的用例,并帮助我们更好地了解访问规则是如何定义的。
创建示例数据
首先,我们将创建一个经理用户。从左侧边栏中选择 GraphQL 选项卡,将以下突变复制到 GraphQL Playground 中,然后点击“播放”按钮
mutation CreateManagerUser {
createUser(input: {
username: "bill.lumbergh"
password: "123456"
role: MANAGER
}) {
username
role
}
}您的屏幕应该如下所示

接下来,让我们通过在 GraphQL Playground 编辑器中运行以下突变来创建一个员工用户
mutation CreateEmployeeUser {
createUser(input: {
username: "peter.gibbons"
password: "abcdef"
role: EMPLOYEE
}) {
username
role
}
}您应该看到以下响应

现在,让我们通过运行以下突变创建一个机密文件
mutation CreateConfidentialFile {
createFile(data: {
content: "This is a confidential file!"
confidential: true
}) {
content
confidential
}
}作为响应,您应该得到以下内容

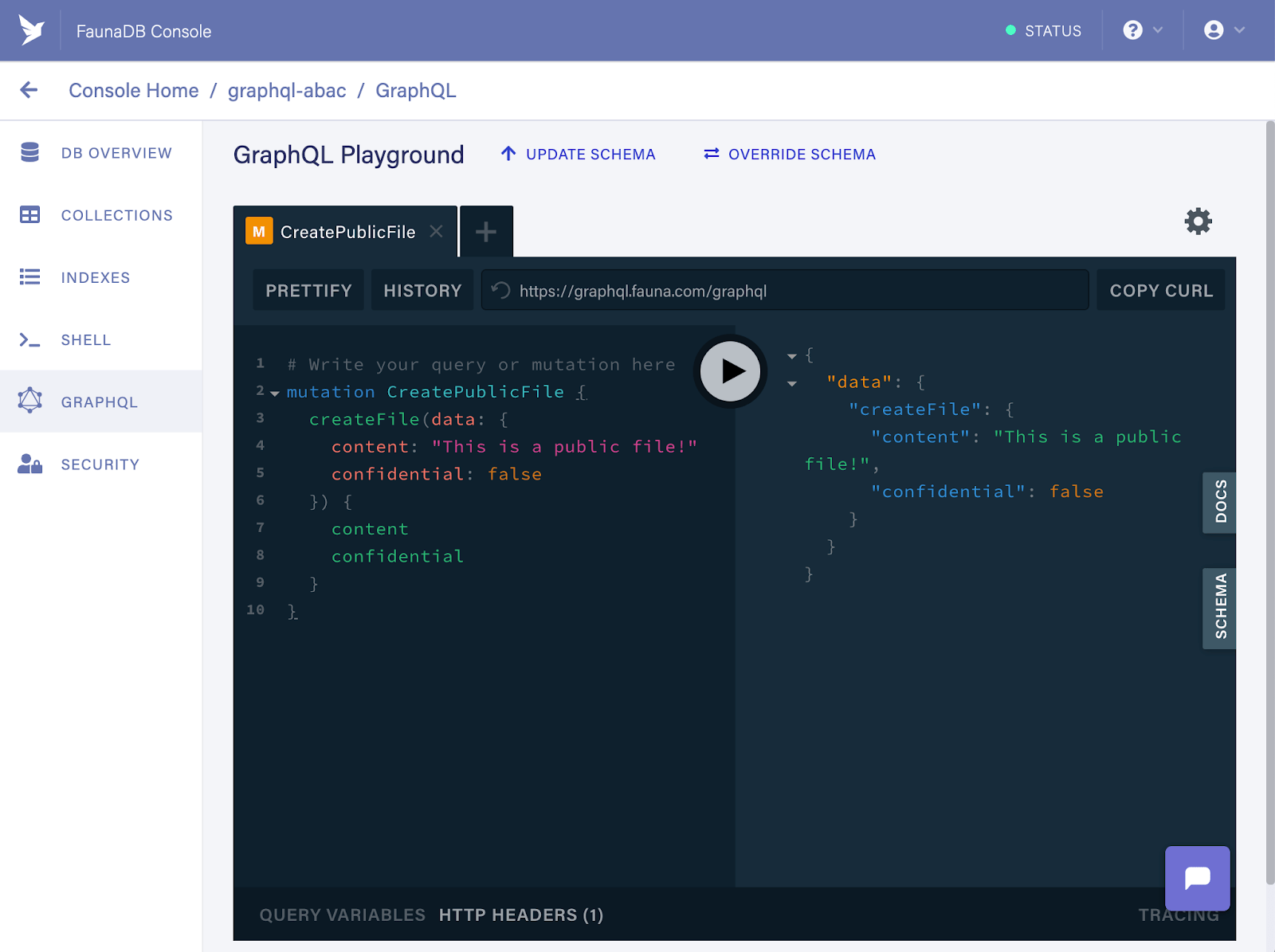
最后,使用以下突变创建一个公共文件
mutation CreatePublicFile {
createFile(data: {
content: "This is a public file!"
confidential: false
}) {
content
confidential
}
}如果成功,它应该提示以下响应
现在所有示例数据都已到位,我们需要访问规则,因为本文是关于保护 GraphQL API 的。访问规则决定了我们刚刚创建的示例数据如何访问,因为默认情况下用户只能访问他自己的用户实体。在本例中,我们将实现以下访问规则:
- 允许员工用户仅读取公共文件。
- 允许经理用户读取公共文件,并且仅在工作日读取机密文件。
您可能已经注意到,这些访问规则非常具体。但是,我们将看到 ABAC 系统足够强大,可以表达非常复杂的规则,而不会影响 GraphQL API 的设计。
此类访问规则不属于 GraphQL 规范,因此我们将在 Fauna 查询语言 (FQL) 中定义访问规则,然后通过从 GraphQL API 执行一些查询来验证它们是否按预期工作。
但是,我们提到的“ABAC”系统到底是什么?它代表什么,它能做什么?
什么是 ABAC?
ABAC 代表 **基于属性的访问控制**。顾名思义,它是一种授权模型,根据**属性**来建立访问策略。简单来说,这意味着您可以编写涉及数据任何属性的安全规则。如果我们的数据包含用户,我们可以使用角色、部门和安全级别来授予或拒绝访问特定数据。或者,我们可以使用当前时间、星期几或用户的位置来决定他是否可以访问特定资源。
本质上,ABAC 允许基于环境属性和您的数据定义**细粒度**的访问控制策略。既然我们知道它可以做什么,让我们定义一些访问规则来提供具体示例。
定义访问规则
在 FaunaDB 中,访问规则以角色的形式定义。角色包含以下数据
角色是通过 CreateRole FQL 函数创建的,如以下示例代码片段所示
CreateRole({
name: "role_name",
membership: [ // ... ],
privileges: [ // ... ]
})您可以在此角色中看到两个重要的概念:**成员资格**和**权限**。成员资格定义了谁接收角色的权限,而权限定义了这些权限是什么。让我们从一个简单的示例规则开始:“任何用户都可以读取所有文件”。
由于该规则适用于所有用户,我们将这样定义成员资格:
membership: {
resource: Collection("User")
}简单吧?然后,我们继续为所有这些用户定义“可以读取所有文件”的权限。
privileges: [
{
resource: Collection("File"),
actions: { read: true }
}
]这直接导致您可以通过我们的 loginUser GraphQL 突变使用用户登录而获得的任何令牌现在都可以访问所有文件。
这是我们可以编写的最简单的规则,但在我们的示例中,我们希望限制访问某些机密文件。为此,我们可以用一个函数替换 {read: true} 语法。由于我们已定义权限的资源是“文件”集合,因此此函数将以查询访问的每个文件作为第一个参数。然后,您可以编写诸如“用户只能访问非机密文件”之类的规则。在 FaunaDB 的 FQL 中,这样的函数是通过使用 Query(Lambda(‘x’, … <使用 Var(‘x’) 的逻辑>)) 编写的。
以下是仅提供对非机密文件的读取访问权限的权限:
privileges: [
{
resource: Collection("File"),
actions: {
// Read and establish rule based on action attribute
read: Query(
// Read and establish rule based on resource attribute
Lambda("fileRef",
Not(Select(["data", "confidential"], Get(Var("fileRef"))))
)
)
}
}
]这直接使用我们试图访问的“文件”资源的属性。由于它只是一个函数,我们还可以考虑环境属性,例如当前时间。例如,让我们编写一个规则,该规则只允许在工作日访问。
privileges: [
{
resource: Collection("File"),
actions: {
read: Query(
Lambda("fileRef",
Let(
{
dayOfWeek: DayOfWeek(Now())
},
And(GTE(Var("dayOfWeek"), 1), LTE(Var("dayOfWeek"), 5))
)
)
)
}
}
]正如我们的规则中所述,机密文件只能由经理访问。经理也是用户,因此我们需要一个适用于用户集合中特定部分的规则。幸运的是,我们也可以将成员资格定义为一个函数;例如,以下 Lambda 仅将具有 MANAGER 角色的用户视为角色成员资格的一部分。
membership: {
resource: Collection("User"),
predicate: Query( // Read and establish rule based on user attribute
Lambda("userRef",
Equals(Select(["data", "role"], Get(Var("userRef"))), "MANAGER")
)
)
}总之,FaunaDB 角色是非常灵活的实体,允许根据所有系统元素的属性定义访问规则,并具有不同的粒度级别。定义规则的位置——权限或成员资格——决定了它们的粒度和可用的属性,并且会因每个特定用例而异。
既然我们已经介绍了角色的工作原理,让我们继续创建示例用例的访问规则!
为了保持整洁,我们将创建两个角色:每个访问规则一个。这将使我们能够在以后需要时以有组织的方式用更多规则扩展角色。但是,请注意,如果需要,所有规则也可以在一个角色中一起定义。
让我们实现第一个规则:
“允许员工用户仅读取公共文件”。
为了创建一个满足这些条件的角色,我们将使用以下查询
CreateRole({
name: "employee_role",
membership: {
resource: Collection("User"),
predicate: Query(
Lambda("userRef",
// User attribute based rule:
// It grants access only if the User has EMPLOYEE role.
// If so, further rules specified in the privileges
// section are applied next.
Equals(Select(["data", "role"], Get(Var("userRef"))), "EMPLOYEE")
)
)
},
privileges: [
{
// Note: 'allFiles' Index is used to retrieve the
// documents from the File collection. Therefore,
// read access to the Index is required here as well.
resource: Index("allFiles"),
actions: { read: true }
},
{
resource: Collection("File"),
actions: {
// Action attribute based rule:
// It grants read access to the File collection.
read: Query(
Lambda("fileRef",
Let(
{
file: Get(Var("fileRef")),
},
// Resource attribute based rule:
// It grants access to public files only.
Not(Select(["data", "confidential"], Var("file")))
)
)
)
}
}
]
})从左侧边栏中选择 Shell 选项卡,将上面的查询复制到命令面板,然后单击“运行查询”按钮

接下来,让我们实现第二个访问规则
“允许经理用户读取公共文件,并且仅在工作日读取机密文件”。
在这种情况下,我们将使用以下查询
CreateRole({
name: "manager_role",
membership: {
resource: Collection("User"),
predicate: Query(
Lambda("userRef",
// User attribute based rule:
// It grants access only if the User has MANAGER role.
// If so, further rules specified in the privileges
// section are applied next.
Equals(Select(["data", "role"], Get(Var("userRef"))), "MANAGER")
)
)
},
privileges: [
{
// Note: 'allFiles' Index is used to retrieve
// documents from the File collection. Therefore,
// read access to the Index is required here as well.
resource: Index("allFiles"),
actions: { read: true }
},
{
resource: Collection("File"),
actions: {
// Action attribute based rule:
// It grants read access to the File collection.
read: Query(
Lambda("fileRef",
Let(
{
file: Get(Var("fileRef")),
dayOfWeek: DayOfWeek(Now())
},
Or(
// Resource attribute based rule:
// It grants access to public files.
Not(Select(["data", "confidential"], Var("file"))),
// Resource and environmental attribute based rule:
// It grants access to confidential files only on weekdays.
And(
Select(["data", "confidential"], Var("file")),
And(GTE(Var("dayOfWeek"), 1), LTE(Var("dayOfWeek"), 5))
)
)
)
)
)
}
}
]
})将查询复制到命令面板,然后单击“运行查询”按钮

此时,我们已经创建了实现和尝试示例用例所需的所有元素!让我们继续验证我们刚刚创建的访问规则是否按预期工作…
将所有内容付诸实践
让我们从检查第一个规则开始:
“允许员工用户仅读取公共文件”。
我们需要做的第一件事是以员工用户身份登录,以便我们可以验证可以代表其读取哪些文件。为此,请从 GraphQL Playground 控制台执行以下突变
mutation LoginEmployeeUser {
loginUser(input: {
username: "peter.gibbons"
password: "abcdef"
})
}作为响应,您应该获得一个秘密访问令牌。该秘密表示用户已成功验证身份

此时,请记住,我们之前定义的访问规则不直接与登录过程中生成的秘密相关联。与其他授权模型不同,秘密令牌本身不包含任何授权信息,而只是一个给定文档的身份验证表示。
如前所述,访问规则存储在角色中,角色通过其成员资格配置与文档关联。身份验证后,秘密令牌可用于后续请求,以证明调用者的身份并确定与其关联的角色。这意味着访问规则在每个后续请求中实际验证,而不仅仅是在身份验证期间。此模型使我们能够动态修改访问规则,而无需用户重新进行身份验证。
现在,我们将使用上一步中颁发的秘密在下一个查询中验证调用者的身份。为此,我们需要将秘密作为 Bearer 令牌 包含在请求中。为此,我们必须修改 GraphQL Playground 设置的 Authorization 标头值。由于我们不想错过用作默认值的管理员秘密,因此将在一个新选项卡中执行此操作。
单击加号 (+) 按钮以创建一个新选项卡,然后选择 GraphQL Playground 编辑器左下角的 HTTP HEADERS 面板。然后,修改 Authorization 标头的值以包含先前获得的秘密,如以下示例所示。确保将方案的值从 Basic 也更改为 Bearer
{
"authorization": "Bearer fnEDdByZ5JACFANyg5uLcAISAtUY6TKlIIb2JnZhkjU-SWEaino"
}在请求中正确设置秘密后,让我们尝试代表员工用户读取所有文件。从 GraphQL Playground 运行以下查询:
query ReadFiles {
allFiles {
data {
content
confidential
}
}
}在响应中,您应该只看到公共文件

由于我们为员工用户定义的角色不允许他们读取机密文件,因此它们已从响应中正确过滤掉!
让我们现在继续验证我们的第二个规则
“允许经理用户读取公共文件,并且仅在工作日读取机密文件”。
这次,我们将以员工用户身份登录。由于登录突变需要一个管理员秘密令牌,因此我们必须首先返回包含默认授权配置的原始选项卡。在那里后,运行以下查询
mutation LoginManagerUser {
loginUser(input: {
username: "bill.lumbergh"
password: "123456"
})
}您应该收到一个新秘密作为响应

复制秘密,创建一个新选项卡,并将 Authorization 标头的值修改为包含秘密作为 Bearer 令牌,就像我们之前所做的那样。然后,运行以下查询以代表经理用户读取所有文件
query ReadFiles {
allFiles {
data {
content
confidential
}
}
}只要您在工作日运行此查询(如果不是,请随时更新此规则以包含周末),您应该在响应中同时获取公共文件和机密文件

最后,我们已经验证了所有访问规则都通过 GraphQL API 成功运行!
结论
在这篇文章中,我们学习了如何在 FaunaDB GraphQL API 之上实现一个全面的授权模型,使用 FaunaDB 的内置 ABAC 功能。我们还回顾了 ABAC 的独特功能,它允许根据每个系统组件的属性定义复杂的访问规则。
虽然访问规则目前只能通过 FQL API 定义,但它们实际上针对每个针对 FaunaDB GraphQL API 执行的请求进行验证。提供对将访问规则指定为 GraphQL 架构定义的一部分的支持已计划在未来实现。
简而言之,FaunaDB 提供了一种强大的机制,可以在 GraphQL API 之上定义复杂的访问规则,涵盖大多数常见用例,而无需第三方服务。
您将如何处理密码重置电子邮件?
如果您需要重置或确认电子邮件,您将需要一个无服务器函数来处理。有一位用户实现了一个混合方法,其中一些 GraphQL 查询由无服务器函数处理,其余则委托给实际的 GraphQL 终结点:https://github.com/ptpaterson/netlify-faunadb-graphql-auth
我们很快就会自己写一些东西来进一步阐明这一点。
您将如何添加一个实体,只有用户可以作为管理员读取和写入,但他们可以选择性地授予一个或多个员工访问权限?
此外,嵌套数据在此示例中也很有用。
第二部分?
使用 ABAC 有很多方法可以做到这一点。我们正在努力制作示例以使事情更加清晰(希望我们也可以很快将其迁移到 GraphQL 中)
因为您基本上在每个 ABAC 权限函数中获得两件事。
– 您要访问的实体
– 想要访问的数据库实体的 Identity()。
我发现很难想出它做不到的事情。例如,您可以添加一个描述可以访问实体的用户类型的属性(并编写一个具有检查该属性是否存在权限的角色)。管理员当然可以更改它,但如果您不希望更改,您也可以在这些权限中阻止它(检查写入是否正在更改它,然后再接受写入)。
除了属性之外,您还可以保留一个列出经理授予访问权限的用户员工的第二个属性,并为其编写一个权限角色。
非常感谢您的反馈,我们将继续努力制作更好的示例,将我上面写的内容转换为代码和教程:)
很棒的教程 - Fauna DB 看起来很有希望,但我发现很难找到指南/教程,特别是关于身份验证的,所以感谢您提供这个教程!
希望看到一个与其他问题相一致的第二部分
1 - 如何处理诸如重置密码(或使用 Google、Github 或替代服务登录)之类的事情
2 - 多租户身份验证。使用待办事项列表应用程序或笔记应用程序的基本示例
一个列表可以有一个所有者和许多合作者 - 他们都可以读/写,但只有所有者可以删除。
一个用户在一个列表中可以是角色 x,但在另一个列表中可以是角色 y(在这种情况下,角色是动态的)。
再次感谢!
嘿,感谢您的赞赏之词。
我们同意我们需要更多身份验证教程,包括专门针对 GraphQL 的身份验证教程。我目前正在努力制作一些真实的示例,我们将写一些关于它们的教程,希望能在 CSS tricks 上发布:)
敬请期待!
感谢分享有关使用 FaunaDB 启动和运行的如此详细的演练。FaunaDB 似乎是快速原型设计/创建具有良好 ABAC 功能的终结点的完美工具。
正如其他人所要求的,我们一定会喜欢涵盖 FaunaDB 与 oAuth、Google 等身份验证服务的示例/文章。